Can You Best The Mysterious Man In The Trench Coat?
Expanding on the Riddler's Problem
in r
March 20, 2016
The latest Riddler puzzle on FiveThirtyEight:
A man in a trench coat approaches you and pulls an envelope from his pocket. He tells you that it contains a sum of money in bills, anywhere from $1 up to $1,000. He says that if you can guess the exact amount, you can keep the money. After each of your guesses he will tell you if your guess is too high, or too low. But! You only get nine tries. What should your first guess be to maximize your expected winnings?
My solution is based on a basic, yet elegant, strategy. The first guess can be selected arbitrarily between $1 and $1000 - let’s say here that my first guess is $ 500. If my guess is correct, then I win (yay!). But since I have just a 1 in 1000 probability of guessing correctly on the first try, I’m probably not done. So if the trenchcoat man says the actual value is higher, my next guess will be the midway point between my first guess and the maximum possible value. Initially, this will be $1000. If the trenchcoat man says the actual value is lower, my next guess will be the midway point between my first guess and the minimum possible value ($1).
So let’s say my guess is too low and the actual value is higher. My second guess would be $750. If I’m correct, I win. If the actual amount is lower, my next guess will be the midpoint between $500 and $750 - remember that I now know it must be within this range.
I can iterate through this process with up to 9 guesses. At that point, if I still have not guessed the amount, I lose.
To simulate this process in R, I wrote the following function
library(dplyr)
library(ggplot2)
library(ggrepel)
theme_set(theme_minimal(base_size = 16))
set.seed(123)
# function to guess money amount using strategy
guess_money <- function(actual, initial, n_tries = 9,
min_val = 1, max_val = 1000,
print_guess = FALSE) {
# set iterator
i <- 1
# while i is less than the max number of guesses, find the median value
# within the possible range. if guess is not correct, reset min_val or max_val
# depending on info trenchcoat man provides
while (i <= n_tries) {
if (i == 1) {
guess <- initial
} else {
guess <- round(mean(c(min_val, max_val)))
}
# print the guess if print_guess is TRUE
if (print_guess) cat(paste0("Guess Number ", i, ": $", guess), sep = "\n")
# if guess is correct, immediately exit the loop and return true
# if guess is not correct:
## if actual is higher than guess, change min_val to guess
## if actual is lower than guess, change max_val to guess
if (actual == guess) {
return(c(win = TRUE, round = i))
} else if (actual > guess) {
min_val <- guess
} else if (actual < guess) {
max_val <- guess
}
# iterate to next round if guess was incorrect
i <- i + 1
}
# at this point still have not guessed the money amount, so lose
# correct i since we didn't really guess the i-th time
return(c(win = FALSE, round = i - 1))
}
As an example, let’s say the actual amount of money is $736 and my first guess is $500. Here’s how that would play out:
guess_money(actual = 736, initial = 500, print_guess = TRUE)
## Guess Number 1: $500
## Guess Number 2: $750
## Guess Number 3: $625
## Guess Number 4: $688
## Guess Number 5: $719
## Guess Number 6: $734
## Guess Number 7: $742
## Guess Number 8: $738
## Guess Number 9: $736
## win round
## 1 9
This tells me the different guesses, as well as the fact that I eventually won (win = 1) in the ninth round.
Of course, there is no reason why I have to choose $500 for my initial guess. What if I instead started at $1?
guess_money(actual = 736, initial = 1, print_guess = TRUE)
## Guess Number 1: $1
## Guess Number 2: $500
## Guess Number 3: $750
## Guess Number 4: $625
## Guess Number 5: $688
## Guess Number 6: $719
## Guess Number 7: $734
## Guess Number 8: $742
## Guess Number 9: $738
## win round
## 0 9
Clearly not the best initial guess. I wasted my first guess and ended up not winning the money. But how do we know which initial guess provides the highest expected value? That is, the initial guess that maximizes my potential winnings regardless of the actual amount of money held by the trenchcoat man?
To answer that question, I calculate the results for every potential initial guess (each integer between 1 and 1000) and every potential actual amount of money (again, each integer between 1 and 1000). This results in 1,000,000 different potential game states. From there, we can calculate the average winnings for each initial guess. These average winnings are the expected value, or what we might expect to win if we always use that amount for the initial guess.
In order to do this in R, I use the Vectorize function to expand my original function to work with multiple game states.
min_val <- 1
max_val <- 1000
actual_vals <- min_val:max_val
guess_vals <- min_val:max_val
data <- expand.grid(actual = actual_vals, guess = guess_vals) %>%
tbl_df()
## Warning: `tbl_df()` was deprecated in dplyr 1.0.0.
## Please use `tibble::as_tibble()` instead.
data
## # A tibble: 1,000,000 x 2
## actual guess
## <int> <int>
## 1 1 1
## 2 2 1
## 3 3 1
## 4 4 1
## 5 5 1
## 6 6 1
## 7 7 1
## 8 8 1
## 9 9 1
## 10 10 1
## # … with 999,990 more rows
result <- with(data, Vectorize(guess_money)(actual = actual,
initial = guess,
min_val = min_val,
max_val = max_val))
both <- bind_cols(data, t(result) %>%
as.data.frame())
both
## # A tibble: 1,000,000 x 4
## actual guess win round
## <int> <int> <dbl> <dbl>
## 1 1 1 1 1
## 2 2 1 0 9
## 3 3 1 0 9
## 4 4 1 1 9
## 5 5 1 0 9
## 6 6 1 0 9
## 7 7 1 0 9
## 8 8 1 1 8
## 9 9 1 0 9
## 10 10 1 0 9
## # … with 999,990 more rows
Now that we have all the potential outcomes of the game, I can calculate the expected winnings for each initial guess and find the best starting point.
exp_val <- both %>%
group_by(guess) %>%
summarize(
win_rate = mean(win),
exp_val = mean(actual * win)
) %>%
ungroup()
exp_val
## # A tibble: 1,000 x 3
## guess win_rate exp_val
## <int> <dbl> <dbl>
## 1 1 0.256 128.
## 2 2 0.256 128.
## 3 3 0.257 128.
## 4 4 0.258 128.
## 5 5 0.259 128.
## 6 6 0.26 128.
## 7 7 0.261 129.
## 8 8 0.262 129.
## 9 9 0.263 129.
## 10 10 0.264 129.
## # … with 990 more rows
exp_val_max <- exp_val %>%
filter(exp_val == max(exp_val))
ggplot(exp_val, aes(guess, exp_val)) +
geom_line() +
geom_point(data = exp_val_max) +
geom_text(
data = exp_val_max, aes(label = paste0("$", guess)),
hjust = -.25
) +
scale_x_continuous(labels = scales::dollar) +
scale_y_continuous(labels = scales::dollar) +
labs(
x = "Initial Guess",
y = "Average Winnings"
)
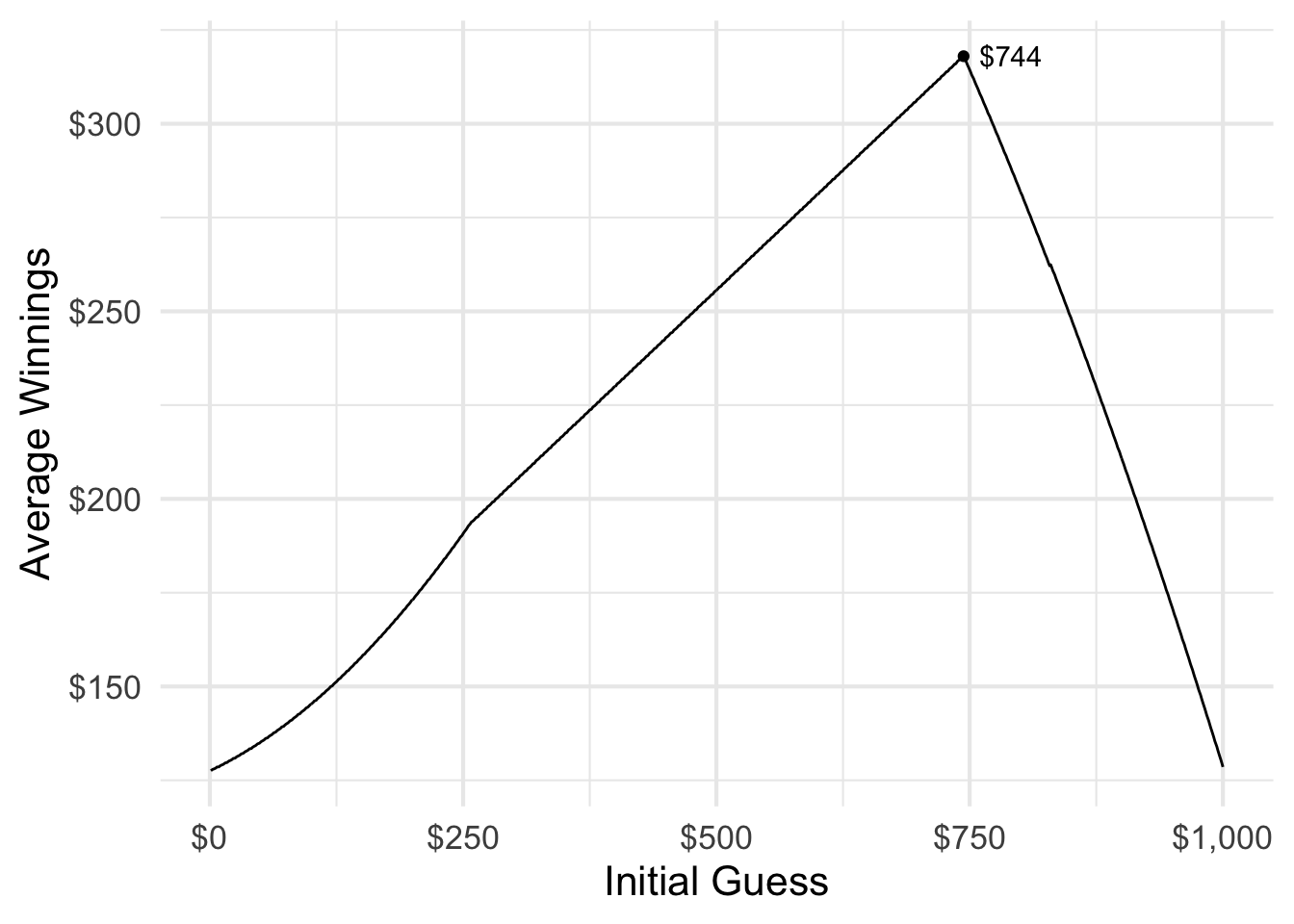
So if you get up to nine guesses, your first guess should be $744. Why is it not $500? Shouldn’t that be optimal, since it minimizes the potential range of values for which you’ll need to initially account? Well, not quite.
There are a range of initial guesses that provide you the same overall win rate.
both %>%
group_by(guess) %>%
summarize(win_rate = mean(win)) %>%
ggplot(aes(guess, win_rate)) +
geom_line() +
scale_x_continuous(labels = scales::dollar) +
scale_y_continuous(labels = scales::percent) +
labs(
x = "Initial Guess",
y = "Win Rate"
)
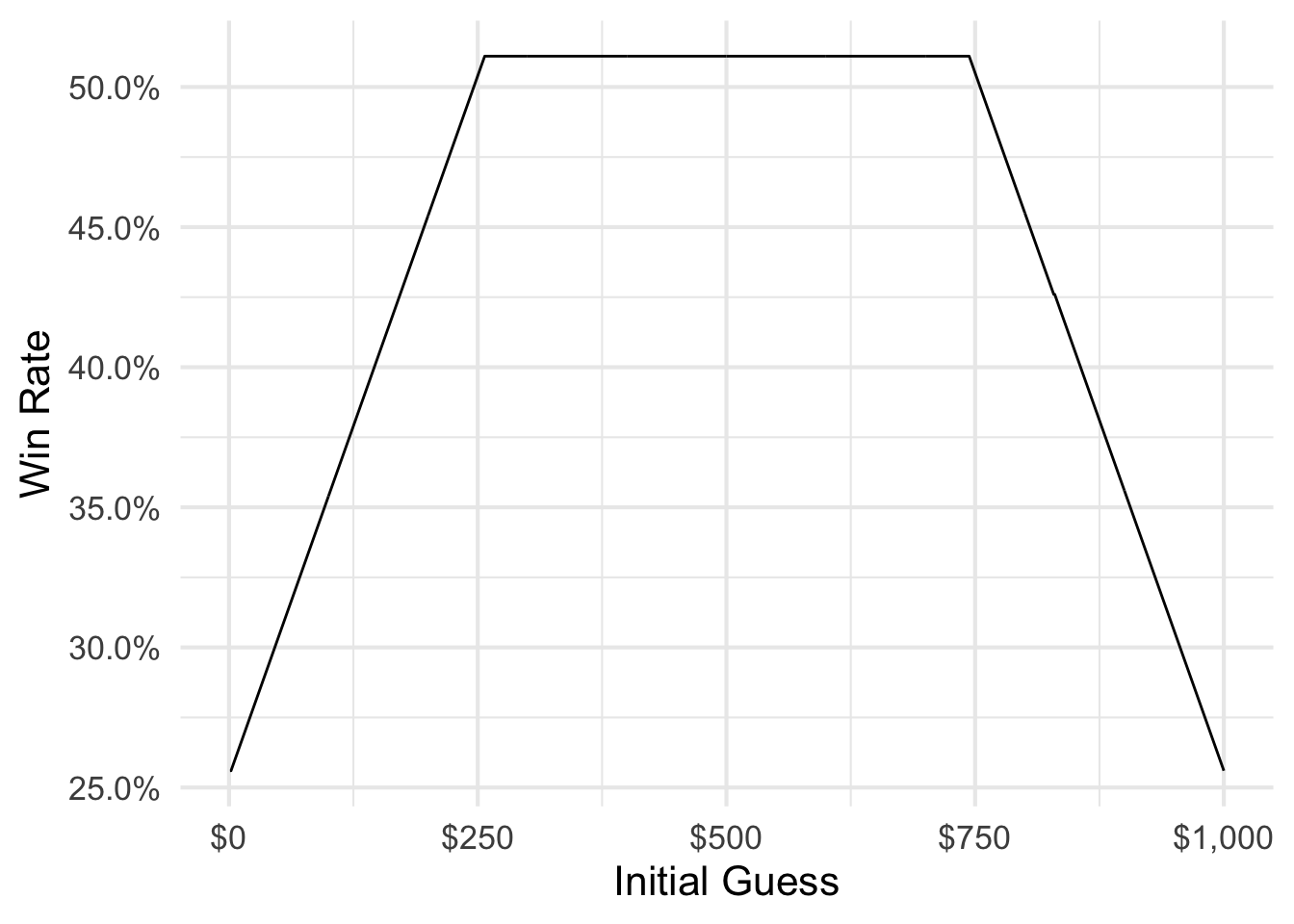
The win rate for initially guessing $300 is the same as for initially guessing $600 - 51.1%. However the expected value for initially guessing $300 is just $204, compared to initially guessing $600 ($281). Which actual values can you win before you run out of attempts?
both %>%
filter(guess == 300 | guess == 600) %>%
mutate(
win = factor(win, levels = 0:1, labels = c("Lose", "Win")),
guess = factor(guess, labels = c(
"Initial Guess: $300",
"Initial Guess: $600"
))
) %>%
ggplot(aes(x = actual, color = win)) +
facet_wrap(~guess) +
geom_vline(aes(xintercept = actual, color = win)) +
scale_color_brewer(type = "qual") +
labs(
x = "Actual Amount of Money",
color = NULL
) +
scale_x_continuous(labels = scales::dollar) +
theme(legend.position = "bottom") +
guides(color = guide_legend(override.aes = list(size = 3)))
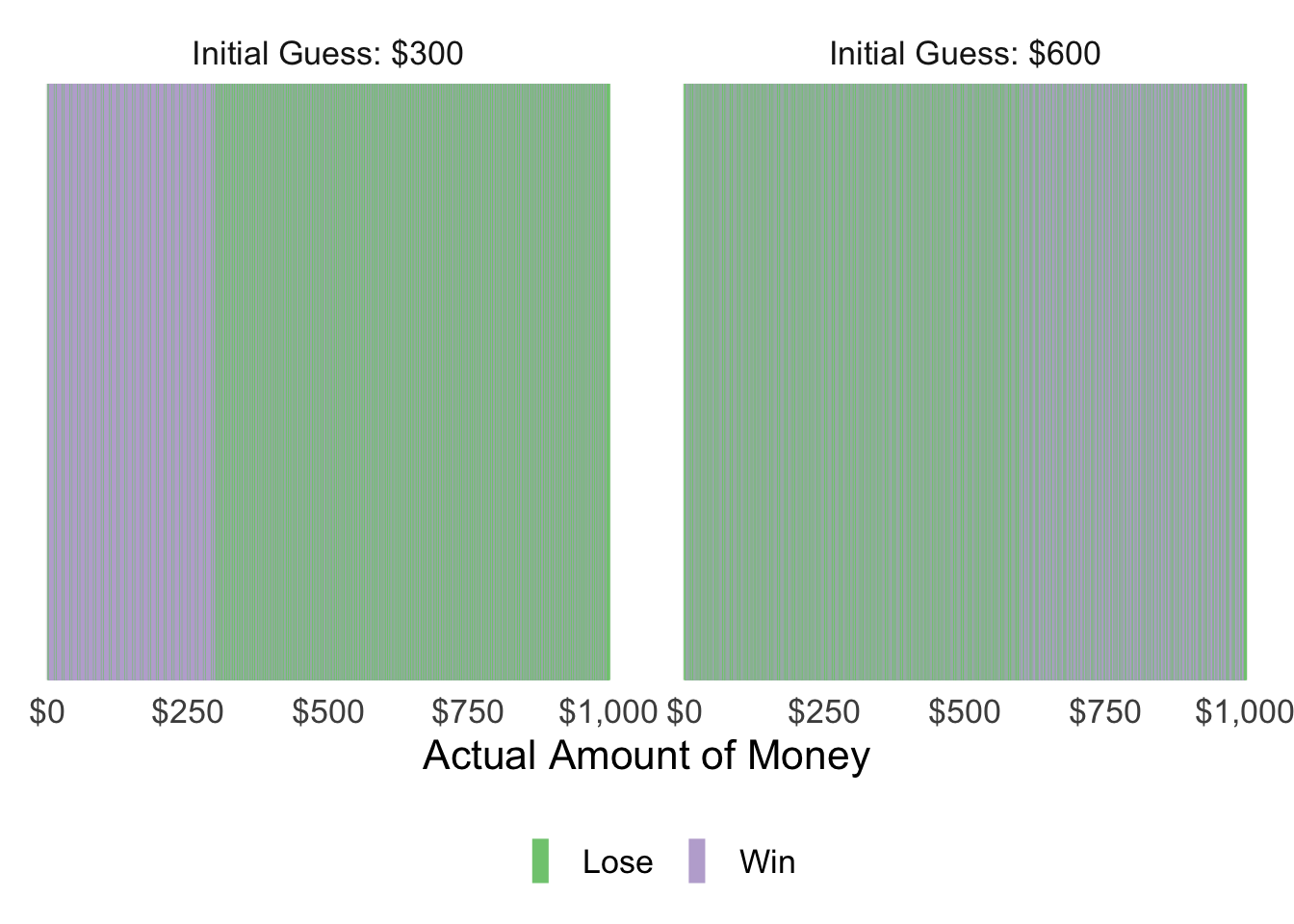
This is the crux: lower starting guesses allow you to win at the same rate, but the value of each set of winnings is lower.
More (or Fewer) Guesses
But what if we modify the game rules so that you get fewer guesses? Or more guesses? How does the number of attempts change the optimal starting guess?
Here I do the same thing as before, but I vary the number of tries the player gets for each set of simulations.
guess_money_mult <- function(n_tries = 1, min_val = 1, max_val = 1000) {
actual_vals <- min_val:max_val
guess_vals <- min_val:max_val
data <- expand.grid(actual = actual_vals, guess = guess_vals) %>%
tbl_df()
result <- with(data, Vectorize(guess_money)(actual = actual,
initial = guess,
n_tries = n_tries,
min_val = min_val,
max_val = max_val))
both <- bind_cols(data, t(result) %>%
as.data.frame()) %>%
mutate(n_tries = n_tries)
return(both)
}
tries_all <- lapply(1:11, function(x) guess_money_mult(n_tries = x)) %>%
bind_rows()
tries_all_exp <- tries_all %>%
mutate(n_tries = factor(n_tries)) %>%
group_by(guess, n_tries) %>%
summarize(
win_rate = mean(win),
exp_val = mean(actual * win)
)
## `summarise()` has grouped output by 'guess'. You can override using the `.groups` argument.
tries_all_exp_max <- tries_all_exp %>%
group_by(n_tries) %>%
filter(exp_val == max(exp_val)) %>%
arrange(-exp_val) %>%
slice(1)
ggplot(tries_all_exp, aes(guess, exp_val,
group = n_tries, color = n_tries
)) +
geom_line() +
geom_point(data = tries_all_exp_max) +
geom_label_repel(
data = tries_all_exp_max,
aes(label = paste0("$", guess)),
show.legend = FALSE
) +
scale_x_continuous(labels = scales::dollar) +
scale_y_continuous(labels = scales::dollar) +
scale_color_brewer(type = "seq", guide = guide_legend(reverse = TRUE)) +
labs(
x = "Initial Guess",
y = "Expected Value",
color = "Number of\nGuesses",
group = "Number of\nGuesses"
)
## Warning in RColorBrewer::brewer.pal(n, pal): n too large, allowed maximum for palette Blues is 9
## Returning the palette you asked for with that many colors
## Warning: Removed 2000 row(s) containing missing values (geom_path).
## Warning: Removed 2 rows containing missing values (geom_point).
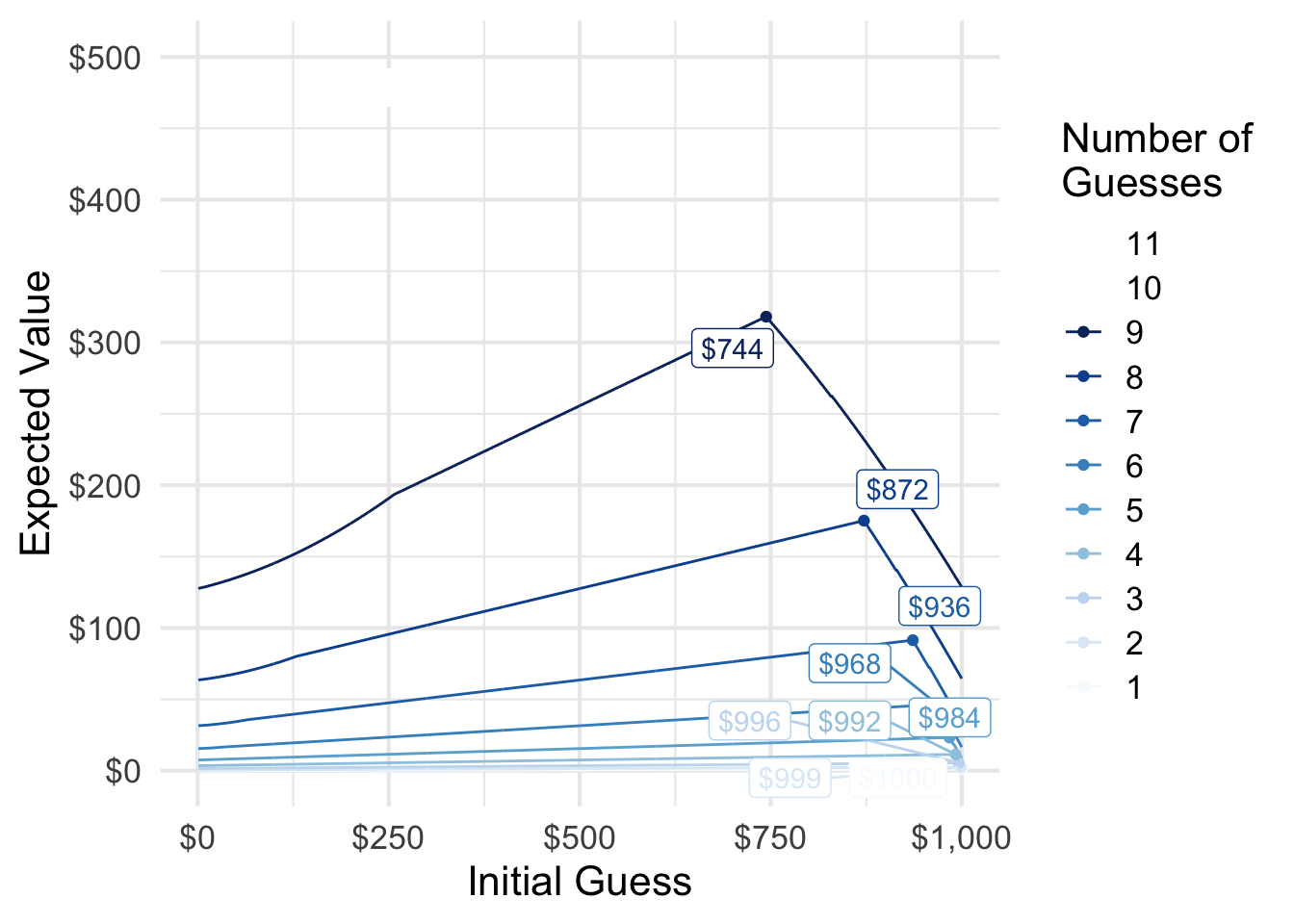
The fewer guesses you receive, the higher your initial guess must be to maximize your expected winnings. If you had 12 11 or more guesses, it simply does not matter what your initial guess is: you can always win using my proposed strategy.
Update: Only Need 11 Guesses
ggplot(tries_all_exp, aes(guess, win_rate,
group = n_tries, color = n_tries
)) +
geom_line() +
scale_x_continuous(labels = scales::dollar) +
scale_y_continuous(labels = scales::percent) +
scale_color_brewer(type = "seq", guide = guide_legend(reverse = TRUE)) +
labs(
x = "Initial Guess",
y = "Win Rate",
color = "Number of\nGuesses",
group = "Number of\nGuesses"
)
## Warning in RColorBrewer::brewer.pal(n, pal): n too large, allowed maximum for palette Blues is 9
## Returning the palette you asked for with that many colors
## Warning: Removed 2000 row(s) containing missing values (geom_path).
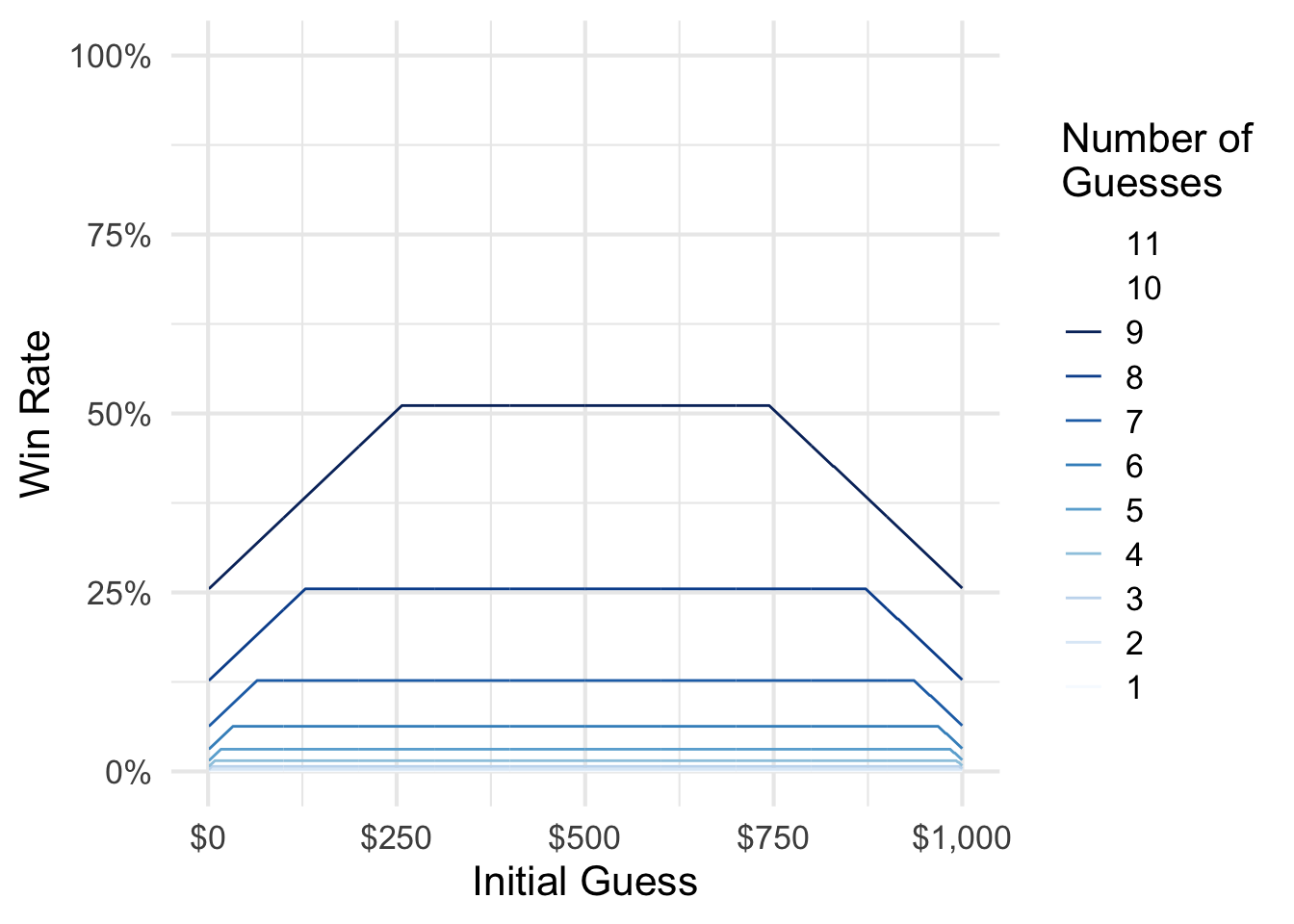
11 is the minimum number of guesses needed to guarantee victory.
Update 2: $744 or $745?
Others have found the optimal starting guess to be $745. This discrepancy is based on how you round each guess. The default R approach to rounding
is complicated, but adheres to international standards.
Original rounding method
min_val <- 1
max_val <- 1000
actual_vals <- min_val:max_val
guess_vals <- min_val:max_val
data <- expand.grid(actual = actual_vals, guess = 744:745) %>%
tbl_df()
result <- with(data, Vectorize(guess_money)(actual = actual,
initial = guess,
min_val = min_val,
max_val = max_val))
bind_cols(data, t(result) %>%
as.data.frame()) %>%
group_by(guess) %>%
summarize(
win_rate = mean(win),
exp_val = mean(actual * win)
) %>%
ungroup() %>%
filter(guess == 744 | guess == 745)
## # A tibble: 2 x 3
## guess win_rate exp_val
## <int> <dbl> <dbl>
## 1 744 0.511 318.
## 2 745 0.51 317.
Always round down
guess_money_floor <- function(actual, initial, n_tries = 9,
min_val = 1, max_val = 1000,
print_guess = FALSE) {
# set iterator
i <- 1
# while i is less than the max number of guesses, find the median value
# within the possible range. if guess is not correct, reset min_val or max_val
# depending on info trenchcoat man provides
while (i <= n_tries) {
if (i == 1) {
guess <- initial
} else {
guess <- floor(mean(c(min_val, max_val)))
}
# print the guess if print_guess is TRUE
if (print_guess) cat(paste0("Guess Number ", i, ": $", guess), sep = "\n")
# if guess is correct, immediately exit the loop and return true
# if guess is not correct:
## if actual is higher than guess, change min_val to guess
## if actual is lower than guess, change max_val to guess
if (actual == guess) {
return(c(win = TRUE, round = i))
} else if (actual > guess) {
min_val <- guess
} else if (actual < guess) {
max_val <- guess
}
# iterate to next round if guess was incorrect
i <- i + 1
}
# at this point still have not guessed the money amount, so lose
# correct i since we didn't really guess the i-th time
return(c(win = FALSE, round = i - 1))
}
result <- with(data, Vectorize(guess_money_floor)(actual = actual,
initial = guess,
min_val = min_val,
max_val = max_val))
bind_cols(data, t(result) %>%
as.data.frame()) %>%
group_by(guess) %>%
summarize(
win_rate = mean(win),
exp_val = mean(actual * win)
) %>%
ungroup() %>%
filter(guess == 744 | guess == 745)
## # A tibble: 2 x 3
## guess win_rate exp_val
## <int> <dbl> <dbl>
## 1 744 0.511 318.
## 2 745 0.51 317.
Always round up
guess_money_ceiling <- function(actual, initial, n_tries = 9,
min_val = 1, max_val = 1000,
print_guess = FALSE) {
# set iterator
i <- 1
# while i is less than the max number of guesses, find the median value
# within the possible range. if guess is not correct, reset min_val or max_val
# depending on info trenchcoat man provides
while (i <= n_tries) {
if (i == 1) {
guess <- initial
} else {
guess <- ceiling(mean(c(min_val, max_val)))
}
# print the guess if print_guess is TRUE
if (print_guess) cat(paste0("Guess Number ", i, ": $", guess), sep = "\n")
# if guess is correct, immediately exit the loop and return true
# if guess is not correct:
## if actual is higher than guess, change min_val to guess
## if actual is lower than guess, change max_val to guess
if (actual == guess) {
return(c(win = TRUE, round = i))
} else if (actual > guess) {
min_val <- guess
} else if (actual < guess) {
max_val <- guess
}
# iterate to next round if guess was incorrect
i <- i + 1
}
# at this point still have not guessed the money amount, so lose
# correct i since we didn't really guess the i-th time
return(c(win = FALSE, round = i - 1))
}
result <- with(data, Vectorize(guess_money_ceiling)(actual = actual,
initial = guess,
min_val = min_val,
max_val = max_val))
bind_cols(data, t(result) %>%
as.data.frame()) %>%
group_by(guess) %>%
summarize(
win_rate = mean(win),
exp_val = mean(actual * win)
) %>%
ungroup() %>%
filter(guess == 744 | guess == 745)
## # A tibble: 2 x 3
## guess win_rate exp_val
## <int> <dbl> <dbl>
## 1 744 0.511 318.
## 2 745 0.511 319.
Session Info
devtools::session_info()
## ─ Session info ───────────────────────────────────────────────────────────────
## setting value
## version R version 4.0.4 (2021-02-15)
## os macOS Big Sur 10.16
## system x86_64, darwin17.0
## ui X11
## language (EN)
## collate en_US.UTF-8
## ctype en_US.UTF-8
## tz America/Chicago
## date 2021-06-01
##
## ─ Packages ───────────────────────────────────────────────────────────────────
## package * version date lib source
## assertthat 0.2.1 2019-03-21 [1] CRAN (R 4.0.0)
## blogdown 1.3 2021-04-14 [1] CRAN (R 4.0.2)
## bookdown 0.22 2021-04-22 [1] CRAN (R 4.0.2)
## bslib 0.2.5 2021-05-12 [1] CRAN (R 4.0.4)
## cachem 1.0.5 2021-05-15 [1] CRAN (R 4.0.2)
## callr 3.7.0 2021-04-20 [1] CRAN (R 4.0.2)
## cli 2.5.0 2021-04-26 [1] CRAN (R 4.0.2)
## colorspace 2.0-1 2021-05-04 [1] CRAN (R 4.0.2)
## crayon 1.4.1 2021-02-08 [1] CRAN (R 4.0.2)
## DBI 1.1.1 2021-01-15 [1] CRAN (R 4.0.2)
## desc 1.3.0 2021-03-05 [1] CRAN (R 4.0.2)
## devtools 2.4.1 2021-05-05 [1] CRAN (R 4.0.2)
## digest 0.6.27 2020-10-24 [1] CRAN (R 4.0.2)
## dplyr * 1.0.6 2021-05-05 [1] CRAN (R 4.0.2)
## ellipsis 0.3.2 2021-04-29 [1] CRAN (R 4.0.2)
## evaluate 0.14 2019-05-28 [1] CRAN (R 4.0.0)
## fansi 0.4.2 2021-01-15 [1] CRAN (R 4.0.2)
## fastmap 1.1.0 2021-01-25 [1] CRAN (R 4.0.2)
## fs 1.5.0 2020-07-31 [1] CRAN (R 4.0.2)
## generics 0.1.0 2020-10-31 [1] CRAN (R 4.0.2)
## ggplot2 * 3.3.3 2020-12-30 [1] CRAN (R 4.0.2)
## ggrepel * 0.9.1 2021-01-15 [1] CRAN (R 4.0.2)
## glue 1.4.2 2020-08-27 [1] CRAN (R 4.0.2)
## gtable 0.3.0 2019-03-25 [1] CRAN (R 4.0.0)
## here 1.0.1 2020-12-13 [1] CRAN (R 4.0.2)
## htmltools 0.5.1.1 2021-01-22 [1] CRAN (R 4.0.2)
## jquerylib 0.1.4 2021-04-26 [1] CRAN (R 4.0.2)
## jsonlite 1.7.2 2020-12-09 [1] CRAN (R 4.0.2)
## knitr 1.33 2021-04-24 [1] CRAN (R 4.0.2)
## lifecycle 1.0.0 2021-02-15 [1] CRAN (R 4.0.2)
## magrittr 2.0.1 2020-11-17 [1] CRAN (R 4.0.2)
## memoise 2.0.0 2021-01-26 [1] CRAN (R 4.0.2)
## munsell 0.5.0 2018-06-12 [1] CRAN (R 4.0.0)
## pillar 1.6.1 2021-05-16 [1] CRAN (R 4.0.4)
## pkgbuild 1.2.0 2020-12-15 [1] CRAN (R 4.0.2)
## pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.0.0)
## pkgload 1.2.1 2021-04-06 [1] CRAN (R 4.0.2)
## prettyunits 1.1.1 2020-01-24 [1] CRAN (R 4.0.0)
## processx 3.5.2 2021-04-30 [1] CRAN (R 4.0.2)
## ps 1.6.0 2021-02-28 [1] CRAN (R 4.0.2)
## purrr 0.3.4 2020-04-17 [1] CRAN (R 4.0.0)
## R6 2.5.0 2020-10-28 [1] CRAN (R 4.0.2)
## Rcpp 1.0.6 2021-01-15 [1] CRAN (R 4.0.2)
## remotes 2.3.0 2021-04-01 [1] CRAN (R 4.0.2)
## rlang 0.4.11 2021-04-30 [1] CRAN (R 4.0.2)
## rmarkdown 2.8 2021-05-07 [1] CRAN (R 4.0.2)
## rprojroot 2.0.2 2020-11-15 [1] CRAN (R 4.0.2)
## sass 0.4.0 2021-05-12 [1] CRAN (R 4.0.2)
## scales 1.1.1 2020-05-11 [1] CRAN (R 4.0.0)
## sessioninfo 1.1.1 2018-11-05 [1] CRAN (R 4.0.0)
## stringi 1.6.1 2021-05-10 [1] CRAN (R 4.0.2)
## stringr 1.4.0 2019-02-10 [1] CRAN (R 4.0.0)
## testthat 3.0.2 2021-02-14 [1] CRAN (R 4.0.2)
## tibble 3.1.1 2021-04-18 [1] CRAN (R 4.0.2)
## tidyselect 1.1.1 2021-04-30 [1] CRAN (R 4.0.2)
## usethis 2.0.1 2021-02-10 [1] CRAN (R 4.0.2)
## utf8 1.2.1 2021-03-12 [1] CRAN (R 4.0.2)
## vctrs 0.3.8 2021-04-29 [1] CRAN (R 4.0.2)
## withr 2.4.2 2021-04-18 [1] CRAN (R 4.0.2)
## xfun 0.23 2021-05-15 [1] CRAN (R 4.0.2)
## yaml 2.2.1 2020-02-01 [1] CRAN (R 4.0.0)
##
## [1] /Library/Frameworks/R.framework/Versions/4.0/Resources/library