Can You Win This Hot New Game Show?
Expanding on the Riddler's Problem
in r
March 9, 2016
So the latest Riddler puzzle on FiveThirtyEight goes like this:
Two players go on a hot new game show called “Higher Number Wins.” The two go into separate booths, and each presses a button, and a random number between zero and one appears on a screen. (At this point, neither knows the other’s number, but they do know the numbers are chosen from a standard uniform distribution.) They can choose to keep that first number, or to press the button again to discard the first number and get a second random number, which they must keep. Then, they come out of their booths and see the final number for each player on the wall. The lavish grand prize — a case full of gold bullion — is awarded to the player who kept the higher number. Which number is the optimal cutoff for players to discard their first number and choose another? Put another way, within which range should they choose to keep the first number, and within which range should they reject it and try their luck with a second number?
My initial thought was to try and solve this problem via simulation. The following code will generate 100,000 rounds of play between two players. For the sake of efficiency, we will draw twice for each player now and consider how the selection of the first or second number influences the outcome of the game.
library(dplyr)
library(magrittr)
library(ggplot2)
set.seed(123)
theme_set(theme_minimal(base_size = 16))
# number of rounds to play
n_draw <- 100000
p1 <- cbind(runif(n_draw), runif(n_draw))
p2 <- cbind(runif(n_draw), runif(n_draw))
head(p1)
## [,1] [,2]
## [1,] 0.28758 0.60241
## [2,] 0.78831 0.02285
## [3,] 0.40898 0.82056
## [4,] 0.88302 0.03657
## [5,] 0.94047 0.23505
## [6,] 0.04556 0.87054
head(p2)
## [,1] [,2]
## [1,] 0.6045 0.79293
## [2,] 0.5197 0.22926
## [3,] 0.9664 0.75221
## [4,] 0.8040 0.14595
## [5,] 0.4763 0.93226
## [6,] 0.8904 0.05215
Naive Players
The key thing to realize is that if the players adopt the same strategy, each player will always have a 50% chance of victory. Let’s consider a very simple strategy first: no matter what happens, always keep the first number. After all, the number is generated randomly so there is no guarantee that the second number will be larger than the first number. How well does player 1 do if both players employ this strategy?
sum(p1[,1] > p2[,1]) / n_draw
## [1] 0.4993
With this strategy, each player has a roughly 50% chance of winning the game. We can also see this is the same if each player always takes the second number.
sum(p1[,2] > p2[,2]) / n_draw
## [1] 0.4988
Okay, so this strategy is a bit naive. Why not be more sophisticated? Perhaps instead, players will only take the second number if their first number is low. An arbitrary cutpoint might be .5. That is, if either player gets a number less than .5 in the first draw, they will take whatever they get in the second draw. How does this strategy work? Here I write a short function to select the appropriate value from each round based on a specified cutpoint.
cutoff <- function(draw, cutpoint = .5){
ifelse(draw[, 1] < cutpoint, draw[, 2], draw[, 1])
}
sum(cutoff(p1) > cutoff(p2)) / n_draw
## [1] 0.5002
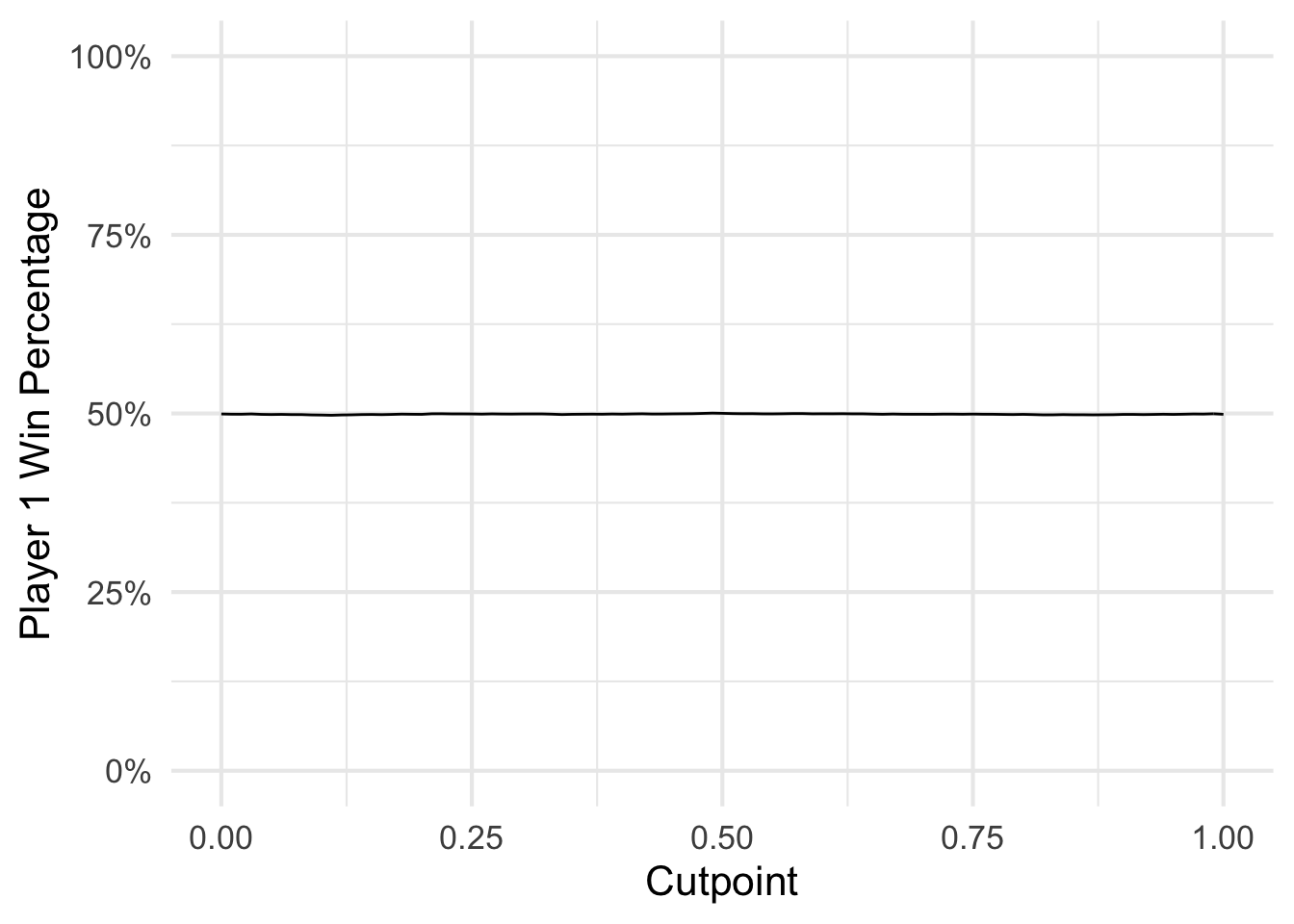
Because each player chose a cutpoint of .5, their probability of winning is still 50%.
This applies to all cutpoints, as long as both players select the same cutpoint.
cutpoints <- seq(0, 1, by = .01)
results <- lapply(cutpoints,
function(cutpoint) sum(cutoff(p1, cutpoint = cutpoint) >
cutoff(p2, cutpoint = cutpoint))) %>%
unlist
results_full <- data_frame(cutpoint = cutpoints,
win = results,
win_prop = win / n_draw)
## Warning: `data_frame()` was deprecated in tibble 1.1.0.
## Please use `tibble()` instead.
results_full
## # A tibble: 101 x 3
## cutpoint win win_prop
## <dbl> <int> <dbl>
## 1 0 49928 0.499
## 2 0.01 49897 0.499
## 3 0.02 49892 0.499
## 4 0.03 49931 0.499
## 5 0.04 49870 0.499
## 6 0.05 49850 0.498
## 7 0.06 49869 0.499
## 8 0.07 49842 0.498
## 9 0.08 49840 0.498
## 10 0.09 49794 0.498
## # … with 91 more rows
ggplot(results_full, aes(cutpoint, win_prop)) +
geom_line() +
scale_y_continuous(labels = scales::percent, limits = c(0, 1)) +
labs(x = "Cutpoint",
y = "Player 1 Win Percentage")
Strategic Players
Okay, so the issue with this analysis thus far is that this assumes the same strategies by both players. What would happen if two players do not use the same cutpoint? After all, the players cannot communicate with one another so there is no reason to expect that they would choose the same cutpoint. Let’s consider what happens if player 1 takes the second number if her first number is less than .5, but player 2 only takes the second number if his first number is less than .9.
cutoff_2 <- function(p1, p2, cut1 = .5, cut2 = .5){
sum(cutoff(p1, cutpoint = cut1) > cutoff(p2, cutpoint = cut2))
}
cutoff_2(p1, p2, cut1 = .5, cut2 = .9) / n_draw
## [1] 0.5688
Hmm, now we’re on to something. Player 1 wins 57% of the rounds. But what if Player 2 knows this and adjusts his cutpoint? And Player 1, expecting this, adjusts her’s? Essentially, we want to determine the equilibrium strategy for this game.
Analytical Solution
So full disclosure: I didn’t do the math on this one. md46135 did the calculus and the full explanation can be found here. The full probability equation is as follows (here, player 1 is named hero and player 2 is named villain):
This is the joint probability of victory for player 1 (or the hero) given four potential states: hero and villain both keep their first numbers, hero keeps her first and villian keeps his second, hero keeps her second and villain keeps his first, and both hero and villain keep their second numbers. In order to calculate the equilibrium strategy for both players, calculate the partial derivatives with respect to h and v:
$$\frac{\partial \Pr(H = 1)}{\partial h} = \frac{1}{2} (-3h^2 + 2hv -v + 1)$$
$$\frac{\partial \Pr(H = 1)}{\partial v} = \frac{1}{2} (h^2 - h + 2v - 1)$$
Then set each derivative equal to 0, and solve for the appropriate values of h and v.
$$h = \frac{\sqrt{5}}{2} - \frac{1}{2}, v = \frac{\sqrt{5}}{2} - \frac{1}{2} $$
Simulation Solution
We can also use R to find this solution via Monte Carlo simulation. This I solved for myself. Essentially we do a grid search over possible combinations of two player cutpoints and find the values which leave each player winning as close to 50% of the rounds as possible.
cut_lite <- seq(0, 1, by = .025)
cut_combo <- expand.grid(cut_lite, cut_lite) %>%
tbl_df %>%
rename(cut1 = Var1, cut2 = Var2) %>%
mutate(p1_win = apply(., 1, FUN = function(x) cutoff_2(p1, p2, cut1 = x[1], cut2 = x[2])),
p1_prop = p1_win / n_draw)
## Warning: `tbl_df()` was deprecated in dplyr 1.0.0.
## Please use `tibble::as_tibble()` instead.
cut_combo
## # A tibble: 1,681 x 4
## cut1 cut2 p1_win p1_prop
## <dbl> <dbl> <int> <dbl>
## 1 0 0 49928 0.499
## 2 0.025 0 51161 0.512
## 3 0.05 0 52259 0.523
## 4 0.075 0 53336 0.533
## 5 0.1 0 54316 0.543
## 6 0.125 0 55302 0.553
## 7 0.15 0 56279 0.563
## 8 0.175 0 57132 0.571
## 9 0.2 0 57917 0.579
## 10 0.225 0 58696 0.587
## # … with 1,671 more rows
ggplot(cut_combo, aes(cut1, cut2, fill = p1_prop)) +
geom_raster() +
# geom_line(data = results_full, aes(cutpoint, cutpoint, fill = NULL)) +
geom_vline(xintercept = sqrt(5) / 2 - (1 / 2), linetype = 2, alpha = .5) +
geom_hline(yintercept = sqrt(5) / 2 - (1 / 2), linetype = 2, alpha = .5) +
geom_point(data = data_frame(x = sqrt(5) / 2 - (1 / 2),
y = sqrt(5) / 2 - (1 / 2)),
aes(x, y, fill = NULL)) +
scale_fill_gradient2(midpoint = .5, labels = scales::percent) +
labs(x = "Player 1 Cutpoint",
y = "Player 2 Cutpoint",
fill = "Player 1 Win\nPercentage") +
theme(legend.position = "bottom",
legend.text = element_text(size = 8))
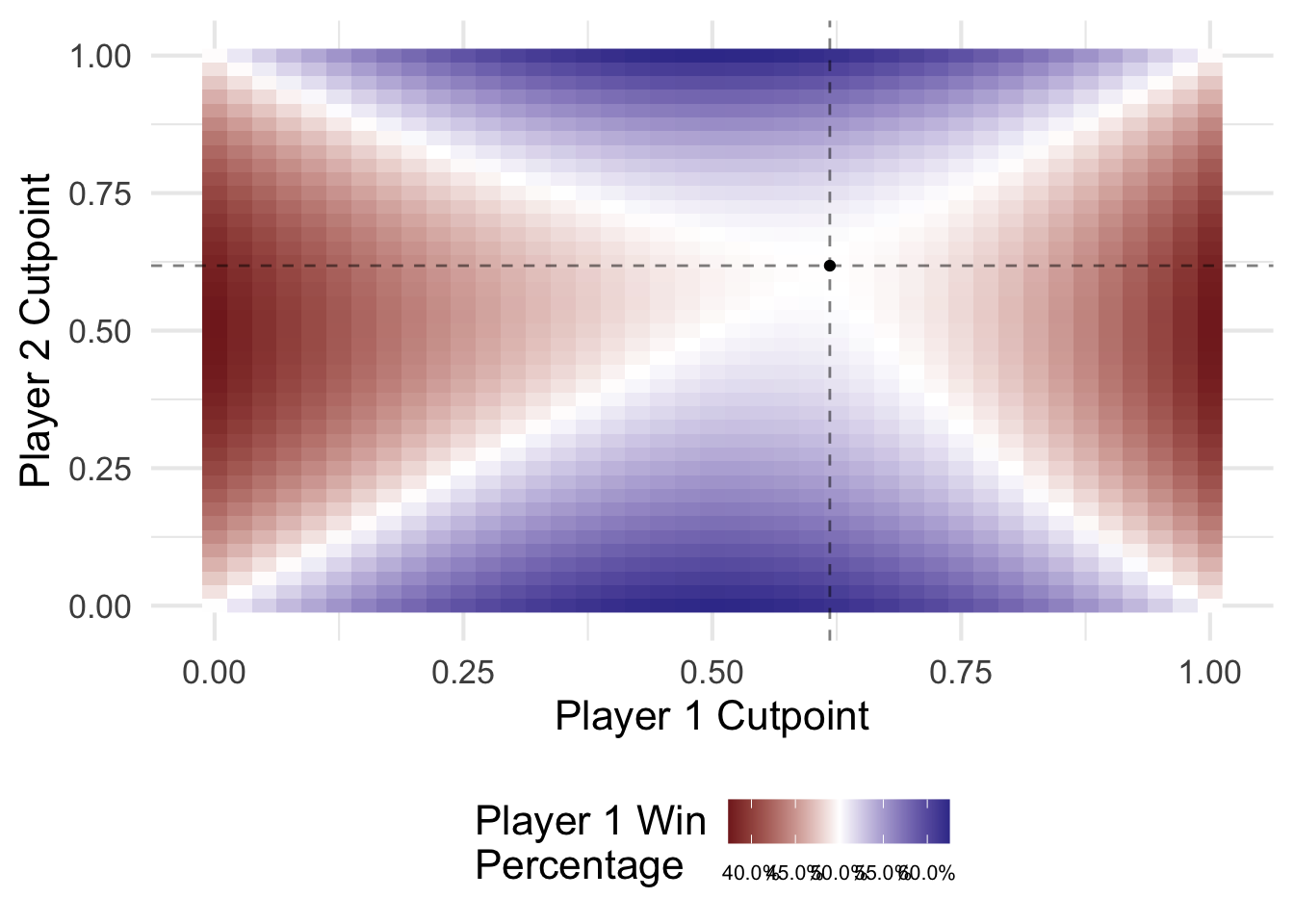
As can be seen above, if either player adjusts his or her strategy, then one of them will be more successful in the long run. In order to maintain the balance, each player should discard their first number if it is less than approximately 0.618.
Session Info
devtools::session_info()
## ─ Session info ───────────────────────────────────────────────────────────────
## setting value
## version R version 4.0.4 (2021-02-15)
## os macOS Big Sur 10.16
## system x86_64, darwin17.0
## ui X11
## language (EN)
## collate en_US.UTF-8
## ctype en_US.UTF-8
## tz America/Chicago
## date 2021-06-01
##
## ─ Packages ───────────────────────────────────────────────────────────────────
## package * version date lib source
## assertthat 0.2.1 2019-03-21 [1] CRAN (R 4.0.0)
## blogdown 1.3 2021-04-14 [1] CRAN (R 4.0.2)
## bookdown 0.22 2021-04-22 [1] CRAN (R 4.0.2)
## bslib 0.2.5 2021-05-12 [1] CRAN (R 4.0.4)
## cachem 1.0.5 2021-05-15 [1] CRAN (R 4.0.2)
## callr 3.7.0 2021-04-20 [1] CRAN (R 4.0.2)
## cli 2.5.0 2021-04-26 [1] CRAN (R 4.0.2)
## colorspace 2.0-1 2021-05-04 [1] CRAN (R 4.0.2)
## crayon 1.4.1 2021-02-08 [1] CRAN (R 4.0.2)
## DBI 1.1.1 2021-01-15 [1] CRAN (R 4.0.2)
## desc 1.3.0 2021-03-05 [1] CRAN (R 4.0.2)
## devtools 2.4.1 2021-05-05 [1] CRAN (R 4.0.2)
## digest 0.6.27 2020-10-24 [1] CRAN (R 4.0.2)
## dplyr * 1.0.6 2021-05-05 [1] CRAN (R 4.0.2)
## ellipsis 0.3.2 2021-04-29 [1] CRAN (R 4.0.2)
## evaluate 0.14 2019-05-28 [1] CRAN (R 4.0.0)
## fansi 0.4.2 2021-01-15 [1] CRAN (R 4.0.2)
## fastmap 1.1.0 2021-01-25 [1] CRAN (R 4.0.2)
## fs 1.5.0 2020-07-31 [1] CRAN (R 4.0.2)
## generics 0.1.0 2020-10-31 [1] CRAN (R 4.0.2)
## ggplot2 * 3.3.3 2020-12-30 [1] CRAN (R 4.0.2)
## glue 1.4.2 2020-08-27 [1] CRAN (R 4.0.2)
## gtable 0.3.0 2019-03-25 [1] CRAN (R 4.0.0)
## here 1.0.1 2020-12-13 [1] CRAN (R 4.0.2)
## htmltools 0.5.1.1 2021-01-22 [1] CRAN (R 4.0.2)
## jquerylib 0.1.4 2021-04-26 [1] CRAN (R 4.0.2)
## jsonlite 1.7.2 2020-12-09 [1] CRAN (R 4.0.2)
## knitr 1.33 2021-04-24 [1] CRAN (R 4.0.2)
## lifecycle 1.0.0 2021-02-15 [1] CRAN (R 4.0.2)
## magrittr * 2.0.1 2020-11-17 [1] CRAN (R 4.0.2)
## memoise 2.0.0 2021-01-26 [1] CRAN (R 4.0.2)
## munsell 0.5.0 2018-06-12 [1] CRAN (R 4.0.0)
## pillar 1.6.1 2021-05-16 [1] CRAN (R 4.0.4)
## pkgbuild 1.2.0 2020-12-15 [1] CRAN (R 4.0.2)
## pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.0.0)
## pkgload 1.2.1 2021-04-06 [1] CRAN (R 4.0.2)
## prettyunits 1.1.1 2020-01-24 [1] CRAN (R 4.0.0)
## processx 3.5.2 2021-04-30 [1] CRAN (R 4.0.2)
## ps 1.6.0 2021-02-28 [1] CRAN (R 4.0.2)
## purrr 0.3.4 2020-04-17 [1] CRAN (R 4.0.0)
## R6 2.5.0 2020-10-28 [1] CRAN (R 4.0.2)
## remotes 2.3.0 2021-04-01 [1] CRAN (R 4.0.2)
## rlang 0.4.11 2021-04-30 [1] CRAN (R 4.0.2)
## rmarkdown 2.8 2021-05-07 [1] CRAN (R 4.0.2)
## rprojroot 2.0.2 2020-11-15 [1] CRAN (R 4.0.2)
## sass 0.4.0 2021-05-12 [1] CRAN (R 4.0.2)
## scales 1.1.1 2020-05-11 [1] CRAN (R 4.0.0)
## sessioninfo 1.1.1 2018-11-05 [1] CRAN (R 4.0.0)
## stringi 1.6.1 2021-05-10 [1] CRAN (R 4.0.2)
## stringr 1.4.0 2019-02-10 [1] CRAN (R 4.0.0)
## testthat 3.0.2 2021-02-14 [1] CRAN (R 4.0.2)
## tibble 3.1.1 2021-04-18 [1] CRAN (R 4.0.2)
## tidyselect 1.1.1 2021-04-30 [1] CRAN (R 4.0.2)
## usethis 2.0.1 2021-02-10 [1] CRAN (R 4.0.2)
## utf8 1.2.1 2021-03-12 [1] CRAN (R 4.0.2)
## vctrs 0.3.8 2021-04-29 [1] CRAN (R 4.0.2)
## withr 2.4.2 2021-04-18 [1] CRAN (R 4.0.2)
## xfun 0.23 2021-05-15 [1] CRAN (R 4.0.2)
## yaml 2.2.1 2020-02-01 [1] CRAN (R 4.0.0)
##
## [1] /Library/Frameworks/R.framework/Versions/4.0/Resources/library